Terraform is a great tool for provisioning infrastructure. One of the best practices that evolve over time as you play more with Terraform, is a directory structure that works best for your project. Some prefer having each component in its own directory so that modification and destruction of resources is easy, while others treat a software stack (e.g. 1 ELB + 2 instances + 1 Elasticache) as a logical unit which should reside together.
The aim of this post is not to re-enforce that idea because that topic has already been written about in depth. Gruntwork’s articles and Reddit discussions give a fair insight into the trade offs of each approach.
But one thing that is common across all approaches is that you will not have a single,
large main.tf file housing all of your resources. You will have to create
a maintainable, extensible, intuitive directory structure. I follow the below
structure:
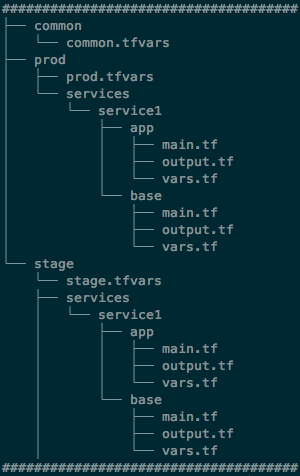
| Directory name | Description |
|---|---|
| common/ | contains common vars which are environment agnostic |
| stage/base/ | contains Terraform code for stage base infra |
| stage/app/ | contains Terraform code for creating the stage app infra |
The variable info is spread across 3 files when we are creating infra in stage/app/ or stage/base/:
| Variable file | Example vars |
|---|---|
| common/common.tfvars | product_name, product_owner_mail_id |
| stage/stage.tfvars | vpc_id |
| stage/base/vars.tf | builds_bucket, iam_role |
| stage/app/vars.tf | elb_name, app_instance_name |
This way we don’t create a very granular directory structure (each component in its own directory) and also limit the coupling (I shouldn’t worry about changing VPC when I want to mess around with the app).
Hence, we have to provide all of them while creating our Terraform plan:
As you can see when we are in stage/service1/app we will have to run our Teraform plans like so:
$ export AWS_DEFAULT_REGION=us-east-2
$ AWS_PROFILE=xyz terraform init -backend=true \
-backend-config="bucket=target-bucket" \
-backend-config="key=bucket-key.tfstate" \
-backend-config="region=${AWS_DEFAULT_REGION}"
$ AWS_PROFILE=xyz terraform plan -var-file=../../common.tfvars \
-var-file=../stage.tfvars \
-out=terraform.tfplan
$ AWS_PROFILE=xyz terraform apply -var-file=../../common.tfvars \
-var-file=../stage.tfvars \
terraform.tfplanSide note: I never export AWS_PROFILE because I want to be sure on every run that I am running Terraform
commands against the right AWS account.
If someone else wants to run the same plan, they need to understand the directory structure (which
they should) and specify the lengthy init, plan, apply commands (which they shouldn’t). The flexibility
of spreading vars trades off the complexity on the command line.
This is where Makefile come to our rescue:
Having a simple Makefile in our target Terraform directories ensures uniformity of approach and eliminates the need to refer to documentation on which are the right commands to run. Now our commands become:
$ AWS_PROFILE=xyz make help
$ AWS_PROFILE=xyz make init
$ AWS_PROFILE=xyz make plan
$ AWS_PROFILE=xyz make applyThis comes with the added benefit of validation i.e. this section ensures that the pre-requisite environment variables are set before running your Terraform commands.
That’s it. Use Makefiles and avail the flexibility without documenting lengthy commands.
Update: Makefiles are useful and there are many people using it. Came across a very comprehensive Terraform Makefile - do check it out.